
How to check canonical meta tags
A canonical tag, sometimes known as a “rel canonical” tag, is a method used for search engine optimization (SEO). The canonical tag communicates to search engines which version of a page is authoritative and should be displayed in the search results for that particular URL.
Using the canonical meta tag gives you more control over your content, which is reason enough for including it on your website. But it turns out there are a few more key reasons why you want to use canonical meta tags.
Why should you include the canonical tag on your website?
Duplicate content is a complex topic, but one that needs to be understood. When search engines scan many URLs with identical (or highly similar) content, it can lead to various SEO issues.
For starters, if search crawlers have to navigate through an excessive amount of duplicate information, they may overlook some of your original content. Extensive duplication may also diminish your capacity to rank highly. Even if your content ranks, search engines may choose the incorrect URL as the “original”.
By utilizing the canonical tag you can avoid the complications that come from “duplicate” or identical content that appears on numerous URLs. In addition, it’s an efficient way to manage duplicate content if you want to keep it on your site.
If your website does not have a canonical meta tag, then Google might not be able to decide which page needs to be shown in the search results. Or it might choose a version of the page you didn’t want shown. To avoid these potential problems, simply include the canonical tag in the head section if it isn’t there already.

Common causes for content duplication problems
Even a small, honest mistake with your content can have a negative impact on your website’s ranking. One of the biggest issues is duplicate content. Duplicate content typically falls into one of the two following categories:
Content causes for duplicate content
- The information is about a specialized subject. Hence, the writing overlaps with what has already been published on the website.
- The author may have cloned a blog post and left in a portion by accident.
- Multiple authors may have cited the same sources and conducted similar research.
- Some content may have been plagiarized from another website and repurposed. This is the worst kind of duplicate content, and there may be major consequences if it’s determined the content was purposely copied.
Technical causes for duplicate content
- The most common cause of duplicate content is an error in the setup of the website or webpage.
- Mobile and desktop page versions.
- Variations of the page that are particular to individual languages.
- Comment or page pagination difficulties.
- URL parameters that are employed in the attribution process.
How to fix duplicate content issues with the canonical meta tag
Rel=”canonical” is the optimal solution for handling duplicate content on your website. A canonical tag on the secondary URLs referring to the main page tells search engines that secondary pages should be viewed as a copy of the URL only. As such, each link, content metrics, and “ranking power” applied to a secondary page should be attributed to the primary URL.
This strategy is especially important to use if there’s duplicate content that’s caused by technical issues.
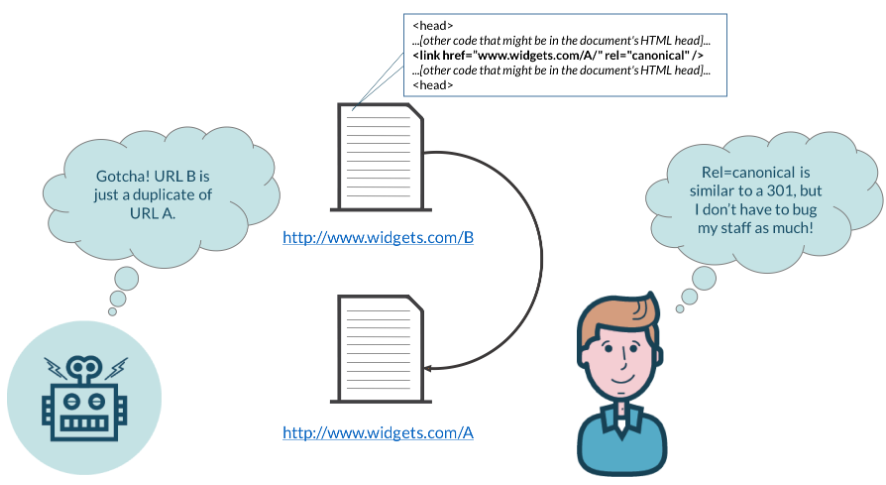
The rel=”canonical” tag is part of a website page’s HTML head and appears as follows:
General Format:
<head> …[other code that might be in your document’s HTML head]…<link href=”URL OF ORIGINAL PAGE” rel=”canonical” /> …[other code that could be in your document’s HTML head]…</head>
If you’re looking for SEO project management software to better manage your workflow, clients, and business – evisio.co is your solution. Try evisio.co for free here!