

Canonical meta tag check
A canonical tag, sometimes known as a “rel canonical” tag, is used to inform search engines that a particular URL corresponds to an authoritative version of a page. In other words, it’s the “main” page among several versions of essentially the same page, which is the one you want to use for SEO ranking.
Using the canonical tag helps you avoid duplicate content issues and all the complications that are brought about when identical content appears on numerous URLs.
In a nutshell, the canonical tag tells search engines which version of a URL you want to be displayed in the search results. If your website does not have a canonical tag, then it’s possible that Google will be unable to decide which page needs to be shown in the search results.
What causes content duplication
When performing an SEO audit, it’s a common occurrence to run into pages that have a different url, but similar or even the same content. While you have likely tried to avoid duplicate content, many times it is created by mistake.
Unfortunately, even the smallest mistakes can have a negative impact on your ranking, and duplicate content is one of them. Aside from human errors and outright plagiarism, the most common cause of duplicate content is an error in the setup of a website or web page.
Duplicate content generally falls into one of two categories:
Content causes
- The information is about a specialized subject; hence the writing overlaps with what has already been published on the website.
- The author may have cloned a blog post and left in a portion by accident.
- Multiple authors may have cited the same sources and conducted similar research.
- Syndication and web scrapers may republish your content (with or without permission) on a different site.
Technical causes
- Mobile and desktop page versions.
- Duplicated content on HTTP and HTTPS pages or pages with and without the “www” prefix in domain names (for example., www.evisio.co and evisio.co), or other issues with a page’s address.
- Variations of the page that are particular to each language (for example., an American English and British English version on different pages).
- Comment or page pagination difficulties.
- URL parameters that are employed in the attribution process or that use session IDs.
Why the canonical tag matters
Duplicate content is a complex topic, but when search engines detect URLs with identical (or highly similar) content, it can lead to various SEO issues. For example,
- If search crawlers must navigate through an excessive amount of duplicate information, they may overlook some of your original content once their crawl budget has been expended.
- Extensive duplication may diminish your capacity to rank highly via keyword cannibalization.
- Even if your content ranks, search engines may choose the incorrect URL as the “original.”
- Link weight from backlinks is an important part of SEO, but if you have links pointing to similar but different pages, you won’t borrow as much authority as you would if they were all pointing to the same page.
If it’s determined that duplicate or similar content is the result of something that was done maliciously, there may be serious consequences.
Using canonical tags helps efficiently manage and prevent all of these duplicate and identical content issues from becoming a problem, while ensuring your preferred URL is used in the search index.
This, in turn, becomes the canonical web page and ensures only one URL is indexed and that this canonical URL is the one that the search engine results pages display. This will help you rank higher for your target keywords, as well as raise the chances that searchers will discover your site.
If you’re not using canonical tags on your website, you have no control over what Google shows in search results.
How to fix duplicate content issues with the canonical attribute
If you’re not comfortable with a lot of coding, the deciding to implement canonical tags into your website’s source code can seem daunting. Luckily, it’s not nearly as difficult as you may imagine and there are a number of free tools you can use to perform a canonical check.
Once you identify duplicate or similar pages, you’ll want to use a canonical tag checker to identify whether or not a URL is already specified to be the “master” page that a search engine indexes
If it one doesn’t exist, you need to include a canonical tag on any subsequent URL referring to the master, canonical page. This is especially important to do in cases that involve duplicate content with technical causes.
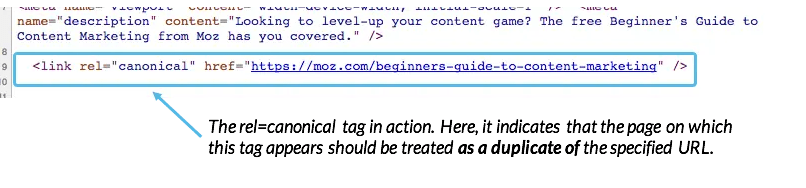
There are several ways you can add a canonical specification, but Rel=”canonical” is the optimal solution for handling duplicate information on your website.
This instructs search engines that a secondary page should be viewed as a copy of a specified canonical URL and that each link, content metrics, and “ranking power” (i.e., link weight) applied to this ancillary page should be attributed to the stated URL.
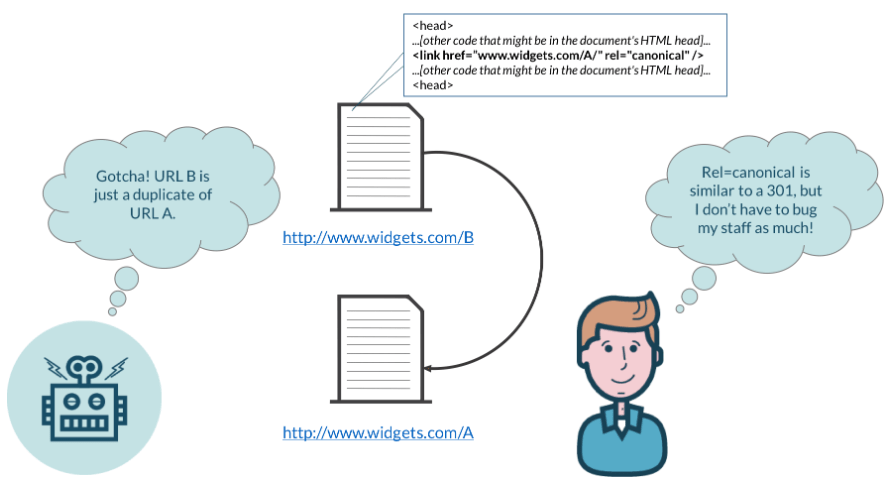
The rel=”canonical” tag is part of a website page’s HTML head and appears as follows:
<head> …[other code that might be in your document’s HTML head]…<link href=”URL OF ORIGINAL PAGE” rel=”canonical” /> …[other code that could be in your document’s head]…</head>
Depending on the tool you’re using, you may be able to specify a canonical URL without adding a HTML tag.
As long as the canonical tag is in the head, duplicate content shouldn’t be a concern.
Other ways to indicate a canonical url
As in most things related to SEO and search engines, there are a number of ways to indicate a page is canonical aside from editing the code of your website or that of individual pages.
If you have duplicates that you don’t need to keep, some webmasters opt to use 3XX, or server-side redirects to point outdated URLs to the appropriate page of your website. One of the most common use of this is when the HTTP/HTTPS and domain issues described above occur.
This is useful because it lets you keep existing URLs, which may still have links pointing at them, while instructing Google to add that link weight to your canonical URLS.
Another way you can indicate to a search engine which page is the master version is by including only canonical URLs in your sitemap. According to Google, all the pages listed in your site map are considered canonical, so you should be careful only to include these URLs in your sitemap.
Otherwise, you run the risk of Google incorrectly deciding which version of your website’s indexed pages are the canonical ones.
Fix canonical issues and streamline everything SEO
Online guides are helpful, but there’s no question SEO can be a complicated undertaking, even for the smallest site. The best and easiest way to make sure every page within your domain has the appropriate canonical tag is by using evisio.
The tool designed to streamline every aspect of search engine optimization, it continually looks for SEO issues that are holding your pages back in the rankings, including missing canonical tags. By automatically scanning your site, it finds any and all SEO problems and provides you with step-by-step instructions for fixing them.
Even better, it automates tedious tasks like reporting, allowing you to spend more time optimizing your website and less time formatting data.
See the power of this tool for yourself. Contact us today to start your free trial.
If you’re looking for SEO project management software to better manage your workflow, clients, and business – evisio.co is your solution. Try evisio.co for free here!