

Using the X-Robots-Tag: Noindex HTTP header
Using meta robot tags and the robots.txt file to control Googlebot has its limitations. You can prevent any page or directory from being crawled with robots.txt, but you won’t be able to manage its indexing, caching, or snippets. Since the robot’s meta tag is part of every HTML file, it is the sole way to regulate crawling, caching, and snippets. For non-HTML and binary files, you have no fine-grained control.
Google has released an innovative answer to this issue. HTTP headers can now be used to instruct web crawlers on where to find particular robot meta tags. X-Robots-Tag is the new header, and it functions and supports the same directives as the traditional robots meta tag, including index/noindex, archive/noarchive, and snippet/nosnippet.
Whether a page on your site contains PDFs, Microsoft Word documents, Excel spreadsheets, ZIP archives, etc., you can now exercise fine-grained control over crawling, caching, and other functions by using this innovative feature. The substitution of an HTTP header for a meta tag makes this possible.
What exactly is X-Robots-Tag?
X-Robots-Tags, which are very similar to robot meta tags, are utilized to govern the crawling and indexing of web pages. But there are some significant distinctions that make the X-Robots-Tag unique. Since X-Robots-Tags are delivered in the headers of the HTTP protocol response and not in the HTML itself, their use is not restricted to files in HTML format.
Do you want to make certain your websites will be removed from search engine results entirely? Using robots’ meta tags will allow you to accomplish this goal. But what should you do if you want a page to be indexed, and you don’t want the image that’s on it to be included? The X-Robots-Tag works perfectly in this scenario, as it does in a few other scenarios as well.
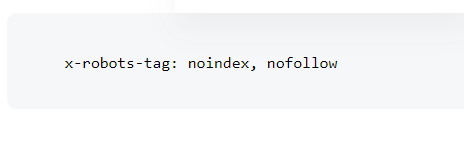
Here’s an example of what an X-Robots-Tag header response looks like:
How often should you make use of the X-Robots-Tag?
You can guide search engines on how to index and crawl various file types by using an X-Robots-Tag, which is not as simple as utilizing meta robots tags. Use the X-Robots-Tag when:
- You must manage how search engines index and crawl non-HTML file formats.
- You must serve directives at the global level (sitewide) instead of the page level.
How to use the X-Robots-Tag with different web servers
Utilizing configuration files located in the website’s root directory is the recommended method to implement the X-Robots-Tag header. The configurations will change depending on the web server that you use.
Using X-Robots-Tag with Apache
It is recommended that you edit the htaccess and httpd.conf server documents. If you need to stop the Apache web server from indexing any files with the.png or.gif extension, you should add the following:

Using X-Robots-Tag with Nginx
The conf file needs to be edited to change the settings. If you want to stop the Nginx web server from indexing any images with the extensions.png or.gif, you can do so by including the following:

Final word on using the X-Robots-Tag
The X-Robots-Tag gives you more fine-tuned control over how your website is indexed and crawled. It’s an optimization tactic that isn’t too difficult to implement once you understand where it goes and how it functions. For those reasons, X-Robots-Tags are definitely worth using.
If you’re looking for SEO project management software to better manage your workflow, clients, and business – evisio.co is your solution. Try evisio.co for free here!